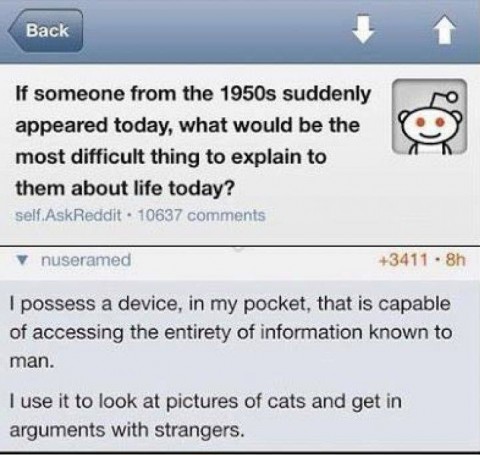
 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my VRM Day presentation at IIW where I lamented that we could have built consumer-side apps to transform commerce but instead we created Angry Birds.
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my VRM Day presentation at IIW where I lamented that we could have built consumer-side apps to transform commerce but instead we created Angry Birds.
We’ve all heard that the the amount of computing power it took to support the manned moon missions is now available in a calculator, or we have at least heard some similar comparison. There is justifiable incredulity that computing power is now so cheap and plentiful that not only can we afford to squander it, but squandering it has become our very highest expression of that power.
Consider for a moment the example used in the meme to make the point. While the vision of putting that wasted capacity to work doing research is noble (I’m an enthusiastic supporter of World Community Grid), it seems rather uninspired. Basically, we should be looking at Wikipedia instead of lolcats, according to the meme. Despite that rather pedestrian example, the point is so compelling as to go viral. I wonder what impact it would have if there were an even better example of personal empowerment than Wikipedia.
You might rightly ask, as a friend recently did, “If consumer-side business apps are so compelling, how come nobody builds them the right way? How come nobody buys the ones we have, crappy though they might be?” Good questions, and ones I believe we know some of the answers to. I’ve identified two root causes.
Architecture
The biggest problem is the prevailing architecture. When we first applied computing to commerce on the vendor side, the hardware and software cost millions of dollars. Financing the systems was possible only by spreading the cost across very large customer populations. At the time, customer data was not inherently valuable, but rather was a byproduct of the system. When I worked as a computer operator for an insurance company in the 1980’s you may have had a decade-old policy but I guarantee we weren’t keeping all that data online. Data was expensive and we kept online only that which was required to conduct day-to-day business and we only archived that which was required to meet compliance obligations. If it wasn’t required for daily operations or compliance we destroyed it. Data was an expensive cost of doing business but it was less expensive than manual processing so it was tolerated as a necessary evil.
Eventually, the growth of computing power and shrinking cost of storage gave us the ability to analyze all that data and suddenly it was no longer an expense but a new source of profit. Companies found they had untapped gold mines in their vaults and set out to unblock all that value. But it wasn’t enough. Soon they began to tweak systems to proactively collect ever more data, from every possible point of interaction with the customer. Save it all, let SAS sort it out. Unfortunately, the moment in time when we collectively realized that data is valuable was also the moment when corporations had more of it than ever before and consumers had none. This locked in the proportions and model for distribution of data. Which is to say there is no distribution per se, just vendors with all your data and you with none. All variations on this model start from this default position.
The corporations have come to believe that consumer data is their birthright.
The result is that the discussion around consumer’s access to their own data is framed in terms of “releasing” it to consumers, but only subsets, under strict terms, and usually under tight constraints on what the consumer can do with it. The consumer is expected to be thankful for whatever access to their data they are granted. The corporation is, after all, doing the consumer a favor, right? (Say “yes” or we revoke your API key.)
In the absence of a better model, all new designs are based on businesses synthesizing new sources for ever more valuable consumer data. These include your browser, your phone, your car, and so on. But if you were to build out commercial software platforms from scratch in an environment with cheap, ubiquitous computing devices and high-quality open-source software, would this vendor-owns-all-data architecture even be possible? If you tried to build Amazon from scratch today and a competitor said “we’ll give you the same market place, the same inventory and the same prices, but we’ll also give you machine-readable copies of all transactional data” someone would build apps to capture and analyze all that data, the app builder would get rich, the competitor market vendor would get rich, the loyal customer would get functionality, and Amazon would be forced to also give you your data or go extinct. Unfortunately, Amazon achieved dominance without any competitive pressure to give you access to your own data, and so they don’t do that. The same is true of every other large vendor.
The premise of Vendor Relationship Management, or VRM, is that with access to their own data, consumers could apply computing power to problems of commerce and of managing their lives. We do this now to some extent, but we have a million different vendors holding our data and charging a million different subscriptions for the privilege. We can’t integrate across these silos and we are locked into specific vendors because the accumulated data is not portable. The vision of VRM is to consolidate all that data into a personal cloud. I may still buy a book from Amazon but my personal cloud lists that book in a collection that also includes books I purchased from my local independent bookstore.. Receipts for all these purchases are captured at the time of sale and loaded into my personal cloud without any manual intervention on my part. The same is true of all my other purchases, utility bills, mortgage or rent payment, car payment, etc. Having captured all this data, I can analyze my own family’s spending and consumption patterns over time. If the consumer-side analytics software is good enough, I might even discover that my daughter is pregnant before Target does.
So, the first big issue we need to overcome is the inertia present in the prevailing big-data, corporate silo architectures. In the absence of a viable competing architecture, corporations have little incentive to change, and why should they? That data is valuable and any accountant will tell you that giving away valuable, income-producing assets means less profit. Of course, it’s actually not a zero-sum game like a balance sheet. Digital data can be copied without diminishing the value of the original copy and if giving it away makes consumers more loyal then the result is more, not less, profit. Convincing data-hoarding corporations to exploit abundance rather than scarcity is the first step.
Cost/Benefit
The second problem is the cost/benefit equation. One of the reasons we look at lolcats and play Angry Birds is because these activities do not require constant vigilance of us. Just the opposite, in fact. Leisure pursuits have become the highest expression of computing power because they relieve us of the stress of daily life. We need software business tools that behave the same way. The lack of enthusiasm for the current and previous crops of Internet of Things “smart” devices and business software designed for lay persons is due in large part to the danger inherent in the usual implementations of these things.
Online banking, for example, requires of the user a much higher level of security hygiene than does Angry Birds. Worse, you mist practice this vigilance not just while signed onto the bank, but at all times when using a device that might someday be used to sign onto your bank. Online banking comes with the advertised functionality, but also incurs the cost of acquiring and practicing online safety habits. If the banking app is reasonably good the cost/benefit nets to the positive side but it can be a close call. On the other hand, it’s almost all upside and virtually no downside to seeing a cat not quite make that leap to the counter top. (The cat may beg to differ.)
One of the most important reasons today’s software is so unsecure is that all the incentives in the system reward lax security. If you spend $1M on security, your competitor who spends nothing is much more profitable, as reflected in their superior financial performance. In order to compete, you too must skimp on security. You’ll regret it if you suffer a breach but, despite the headlines, that’s actually a relatively rare event. Predictably, this drives a race to the bottom. Investment in software security is now mostly a post-breach phenomenon and eternal vigilance is your cost of online banking, or any other non-leisure activity that involves even a modest amount of personal risk.
A different sort of cost/benefit issue exists in so-called “smart” devices, the best (i.e. worst) example of which is lighting. The first requirement of any “smart” device is to act like the thing it replaces. What the first crop of device manufacturers failed to realize is that a bulb and a switch are different parts of the same system. You should therefore improve them as a system. Making either of these operate from your phone is cool, but not something you’d actually want to use – as the mechanical switch and dumb bulbs installed in your house today probably attest. What manufacturers like Philips and Belkin brought to market are a bunch of “smart” switches that operate dumb bulbs, and a bunch of “smart” bulbs which require you to duct tape the dumb wall switch to the ‘ON’ position. Nobody offers a smart bulb/switch set. After the novelty of controlling the light from the phone wears off many people decide “smart” devices are actually pretty stupid and then uninstall them. The requirements to use the phone handset to control the lights, of having to duct-tape the wall switch to the ‘ON’ position to make it all work, the loss of basic lighting control functionality when the Internet is down, combined with the extravagant retail price of the hardware, all add up to an operational cost which far outweighs the benefit of “smart” lighting.
But a truly smart switch is really the user interface to send a signal, and a truly smart bulb is a receiver and actuator of such signals. If the switch passes power through to the bulb at all times, if flipping it sends the required signal, and if the bulb then receives the signal and performs simple on/off actions, then the pair of devices can directly replace the equivalent dumb versions of a switch and bulb. Anyone who has ever operated a standard toggle switch and bulb will be able to operate this smart lighting system without any training or the need to whip out a phone. The truly smart lighting works without Internet connectivity because the signalling is all local, which means the device talks to you first rather than to the manufacturer. If you can replace the dumb switch and bulb with smart versions and cannot tell the difference in normal operation, then there is no incremental cost but considerable benefit in doing so.
Of course, such a system must be capable of local signaling which in turn implies you get the data before the device manufacturer. In fact, there’s a possibility you might block the data from getting back to the manufacturer and just keep it local if you know a bit about networking. The notion that you might be the first and only user of your own data is called personal sovereignty. Where I live in the United States, the Constitution was supposed to guarantee the sovereignty of citizens. The constitution never anticipated digital technology, though. Not only does the prevailing software architecture not recognize your sovereignty as the first owner of your own data, it is more accurate to say that your sovereignty is a direct and urgent threat to the prevailing architecture.
In the absence of personal clouds, consumers as first owners of their own data is unthinkable.
In the presence of personal clouds and cloud apps, consumers as first owners of their data is inevitable.
Think about that for a moment. Nearly all of the computing infrastructure on the planet is designed on the dual premises that 1) data is valuable; and 2) whoever builds the device or service has an absolute right to the data, even to the exclusion of the person to whom the data applies. So it’s my TV but LG’s data. It’s my home automation but it’s Insteon’s data. It’s my cart full of groceries, but even though I was there physically participating in the sale, it’s still the store’s data and only the store’s data.
Changing this situation is the reason for Personal Clouds. Putting all that spare computing power to better use will require all those vendors to provide not just an e-receipt, but specifically a machine-readable e-receipt, or an API that we can use to fetch our data on demand. The chicken-and-egg of this situation is that without apps, there is little demand to squirrel away our transaction data, and without a bunch of data there is little interest from developers. However, it only takes a few seeds to make an alternative architecture take off. It takes someone who believes enough to build the platform and trust that people, data and apps will come.
For example, imagine being the first grocery loyalty company to make the line-item purchase data available to consumers. The moment we have a basic app to display, search, and summarize line-item grocery data, that company will instantly become the most profitable loyalty program vendor on the planet. Other loyalty program vendors will wonder why they ever thought customer data was a zero-sum asset and they too will start giving it away just to remain viable. The more consumers take custody of their own data and extract value from it, the more value corporations will realize in sharing transaction data directly with the other transaction participants.
Similarly, in a world where consumers get to choose whether device data gets out of their home network and back the device vendor, devices that require a connection to the vendor to function will find few buyers and eventually end up on the discount rack at the back of the store. In that environment, device manufacturers will change their business model to provide value-added services, friendly dashboards and/or great analytics in order to earn the customer’s trust and a share of the data. They’ll need to give you a good reason to let it out because the cloud is by default private and it will take some affirmative action on your part before they see that data.
What’s next
The good news is that the only thing keeping us locked into the current architecture is inertia. There’s a lot of infrastructure built around what Doc Searls calls the calf-cow model but one or two good applications built on a new person-centric architecture can be the trickle that becomes a flood and eventually displaces the old model. I spent last week with a group of people dedicated to doing exactly that. The technology needed to build a person-centric platform has been around for a while. The only thing missing was someone with sufficient faith in the new business model to plug the pieces together with the controls facing the user and then trust the user to drive it. Because this threatens the existing model and potentially shakes up entire industries, there will be considerable push back. Those who benefit from the current system want to keep that calf-cow relationship in place. They want you to be wholly dependent on them for all your information needs, even information that you generate. They won’t like a new architecture in which you get to keep as private some of the data they now take for granted.
But we can’t keep walking around with the power of a 1980’s mainframe on our hip reserved exclusively for cartoon games and crazed cats. Even in the absence of some better alternative, we have this vague uneasiness and a bit of guilt that those wasted MIPs could have been put to good use. We want the Internet of Things but we want it to serve people. We want the Internet of People and Things. (Hence the name of my company, IoPT Consulting.) When we transact business, we want our own copy of that transaction automatically delivered to our personal cloud. We want applications to help us index, search, sort, summarize and analyze all our new-found data. And when we get all that, vendors clinging to the calf-cow model will have to get on board or get put out to pasture. Then that spare computing power will provide some real benefit beyond distracting us from the real world. We’ll use it to make the real world better.
This is the mission of the group I’m calling “The Santa Barbara Crew” until I’m out from under non-disclosure: providing serious, business-grade software, built on VRM principles, using personal clouds as the data store, with least possible risk and maximum benefit to users. This will transform commerce even more than it did when we computerized the vendors. The Internet of Things, if built correctly with people at the center, will transform the world more than commerce ever did. We (I say “we” because I’m participating in this project) plan to deliver all those things. It won’t be compromised based on what we think some or other vendor will or won’t accept. It’s designed based on what you or I would insist on if we were building out commercial IT infrastructure today from scratch. More importantly, it’s the thing I think you’d want to use if given the choice. Get ready because that choice is coming your way soon.
What will you do when that opportunity comes?
Will you remain a calf, forever stuck in the vendor’s pasture?
Or will you claim your own sovereign future?
Leave a Reply