Owners of Samsung’s “smart” TVs are now reporting that streaming apps running on the TVs are inserting Pepsi ads into user-owned content stored locally on their PCs and NAS drives. In nearly identical stories, GigaOm and Ars Technica report that this happens for Plex and Foxtel apps running on the TVs.
In addition to the obvious privacy implications, this renders visible a new category in the monetization field: legalized theft of intellectual property.
If you recall the arguments around web search, framing and deep linking, the damage claims arose from money made on the value of the content by people who did not own the content and without permission of the content owners. It was, according to various legal arguments, theft of intellectual property rights, conversion, dilution of the market, etc.
In this case, Samsung is monetizing content you stream locally without regard to who owns the content. There is every reason to believe the content is yours since every smart phone made today takes movies. It’s a point of pride for Samsung who tout their high quality cameras and sensors made to do exactly that. Samsung unquestionably understands the concept of user-generated content and the high probability that the content into which they are inserting commercials is home movies of your cat(s), your kid(s), someone’s birthday party, or your vacation. Maybe you are showing home movies of your recently departed loved one at the wake and suddenly Samsung inserts the Pepsi commercial. (One only hopes it is at least the “Pepsi brings you back alive” campaign from years past.)
The point is, Samsung has no way of knowing anything about the content or the context, only that you find it interesting enough to watch therefore it is valuable enough to monetize, and Samsung believes they have the right to do so.
Because they manufactured the display.
I realize suggesting that Samsung believes they have a right to impose these ads on you may sound a bit hyperbolic, so let’s look at their Privacy Policy–AdHub Supplement:
When you use a Samsung service that includes ads provided by AdHub, AdHub receives certain information about your device. This information may include the device’s hardware model, IMEI number and other unique device identifiers, MAC address, IP address, operating system version, and settings.
In addition, the first time you visit a service that displays ads by AdHub, Ad Hub will assign your device a random ID number, which will be sent back to AdHub each time your device gets a new ad from AdHub.
When AdHub displays an ad to you, AdHub logs the fact that your device received that ad, as well as the webpage or other place where you viewed it.
This leaves no doubt that Samsung is assigning unique tracking IDs to each device capable of rendering content and ads. In order to access the features of the phone, tablet, smart TV or whatever, you are required to have a Samsung account. This attaches your personally identifiable data to each Samsung smart device and correlates those devices under a single umbrella account. Everything that is trackable on the devices is personally identifiable back to the device owners.
Whether or not you trust Samsung as custodian of your private data, the real question is how much you trust the advertisers and publishers that Samsung invites into your device through their AdHub. Though Samsung doesn’t share with them the information collected by Samsung, they do something even better. Samsung gives these third parties direct access to your device, tells you up front that your data will be collected by these third parties, then disclaims any responsibility for what those third parties might do with that privileged access. Samsung remains cozily wrapped within a cloak of anonymity and a blanket liability shield:
Third-party advertisers may use web beacons in their ads in order to collect information about users who view their ads, including through cookies, beacons and similar technologies. Samsung does not control the data collection and use practices of these companies.
Samsung next states their right – there’s that word again – to impose these terms on you. The last part of the policy supplement states that “you can opt out of receiving targeted advertising from AdHub” but notes that that if you do “you will continue to see ads, but they may be less relevant to you because they will not be based on your interests.” In other words, haven’t opted out of any of this data collection, only whether it is used to deliver targeted ads. Everything upstream of that, including the personally identifiable data collection and all the various uses to which that may be put, both by Samsung and it’s army of anonymous advertisers, is protected under the contract. Should you choose to operate the device without registering it to a Samsung account, the piece that makes your use of the device personally identifiable and provides the context of all your other devices, you don’t get to use the features for which you purchased the device.
Let’s be real clear about this. You unquestionably own all rights to content that you create, including the right to monetize that content or to make the choice to not monetize it. You are watching the content in the privacy of your own home. It is running over cables, switches, routers and NAS devices that you personally own. You are the one paying for the electricity and bandwidth. But if the smart device on which you render the content bears a Samsung nameplate, they can force you to watch ads as a prerequisite to render that content, whether you like it or not. Not only is Samsung monetizing your content, they are monetizing your viewing of your content.
Whatever we may think of this, we need to be asking what’s next? Will Motorola, Linksys and Netgear claim a right to insert ads into your privately owned, user-created, streamed content because they manufactured the cable modem, switch and router, respectively? Will Western Digital, Buffalo, or Synology claim a right to insert their ads into your privately owned streamed content because they made the NAS drive?
All of these “smart” components are in the path between where your content is stored and where it is displayed. All are essential for the content streaming to work. All have the processing capacity to insert ads into your content, and all come with Terms of Service and Privacy Policies that you agreed to sight unseen. Samsung may render the content but there is no content to render without all of these other components. Samsung was merely the first to stake their claim but every device in the chain has no better or worse standing to claim a right to insert ads into your streamed content than does Samsung. Do you believe none of them will assert that right once Samsung establishes it? What, exactly, do you believe will stop them?
Let’s do the chess thing and think ahead a move or two. What happens if someone figures out how to disable the ads and distributes a root kit or firmware patch? If that qualifies as anti-circumvention under the DMCA it would be a felony. Will we not have the right to root our TV, just like we do/don’t have the right to root our phone? What happens if a downstream device like the TV happens to interrupt the stream right in the middle of the ad being inserted by an upstream device like the switch or NAS drive? Will Linksys start charging Samsung and Synology for access to your in-home network, the same way that ISPs want to charge Netflix, Amazon and Hulu for bandwidth that has already been paid for at both ends? Because if you are not the ultimate arbiter of what happens on your private home network, then it is up to the courts and corporations to say what happens there.
Let’s think another chess move ahead. US law sets a pretty high bar before law enforcement officers can invade the sanctity of your home. True, these are greatly eroded lately, but your home is where you enjoy the most privacy protection against being recorded in video or audio, and physically searched. But if your TV, phone, game console, robots, toys, appliances, baby monitors and security systems are all live-streaming to corporate entities, law enforcement no longer have to clear that high hurdle. Most companies, especially small start-ups, won’t stand up to government information requests. Do you worry that “this call may be recorded for quality assurance”? Now everything you say in your living room, bedroom, bathroom, car, and your side of every phone call will be recorded for quality assurance and delivered to law enforcement during discovery, even if you aren’t the target of the investigation. You will have more privacy in your front yard than in your own home.
None of these scenarios are all that farfetched in a world where manufacturing a device confers the right to mediate the content transmitted or rendered on that device in a private setting. We consumers don’t read the contracts to which we are bound when we buy these devices and it doesn’t seem likely we’ll start any time soon. We keep buying the devices despite frequent news stories detailing ever more invasive privacy invasions and it doesn’t seem likely we’ll stop buying them any time soon, either. These practices generate net-new revenue for the device manufacturers so, short of them stepping on one another, there’s no chance they will stop voluntarily any time soon or, for that matter, ever.
When you can be forced to watch an ad before viewing content you personally created, there is no neutral, no middle ground, no shred of privacy left to give up that isn’t already being taken from you without your consent. The only options left are to accept the commoditization of our intimate lives, or else to actively protest and demand regulatory protection of our privacy rights and strong enforcement.
If you believe that there is anything at all in the world to which you have a right of privacy, this moment in our time is the last chance you will ever have to demand it before the window of opportunity slams shut and you are rendered effectively naked in the panopticon of life. Anything short of active opposition now is acquiescence. We need to be angry and we need to hold our elected officials accountable to represent our interests for once. Unfortunately, it doesn’t seem likely we’ll start doing that any time soon, either.
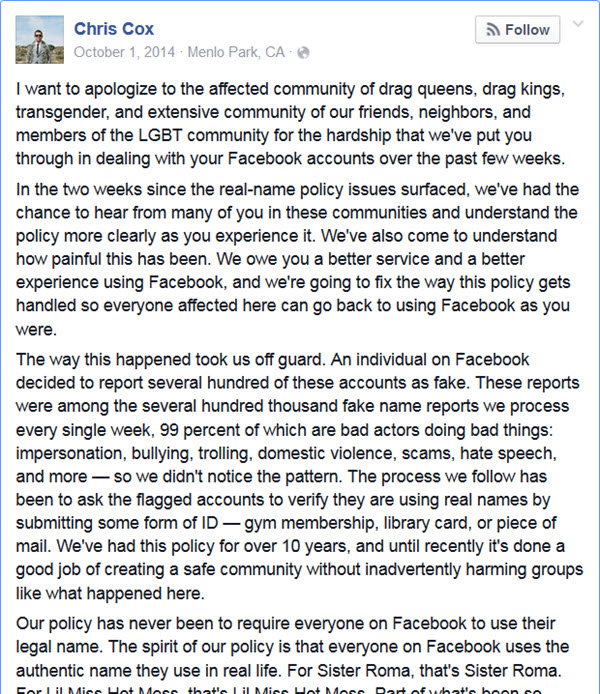
 A few hours ago, Marketing Week published an article in their Trends section titled
A few hours ago, Marketing Week published an article in their Trends section titled 
 The one area in which the authors found some nuance was privacy concerns. It is unfortunate that the result of granularity in this category is to drastically understate the relevance of privacy in consumer minds as compared to the other categories. The effect is apparent in the summary that Marketing Week uses when referring to the article from elsewhere on the site: Consumers cite cost and lack of usefulness as barriers to adoption. No, they didn’t. If you combine both of the Privacy categories, there is a total of only 6 percentage points separating Cost (45%), Relevance (44%), and Privacy (39%). Complexity (23%), which is the next closest category, comes in a distant 12 points below Privacy. The concerns expressed seem to cluster around Cost, Relevance and Privacy as the barriers to adoption. Odd that privacy would get dropped like that.
The one area in which the authors found some nuance was privacy concerns. It is unfortunate that the result of granularity in this category is to drastically understate the relevance of privacy in consumer minds as compared to the other categories. The effect is apparent in the summary that Marketing Week uses when referring to the article from elsewhere on the site: Consumers cite cost and lack of usefulness as barriers to adoption. No, they didn’t. If you combine both of the Privacy categories, there is a total of only 6 percentage points separating Cost (45%), Relevance (44%), and Privacy (39%). Complexity (23%), which is the next closest category, comes in a distant 12 points below Privacy. The concerns expressed seem to cluster around Cost, Relevance and Privacy as the barriers to adoption. Odd that privacy would get dropped like that.
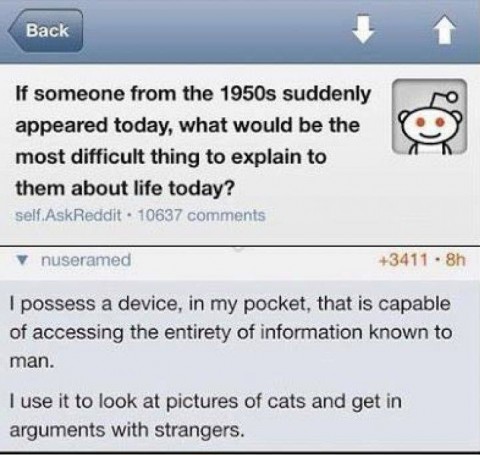 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my