The “Facebook problem” is real and it’s bad. Whatever else you get from this, I’m not trying to play down the impact and continuing risk of data custodians who betray our trust.
It’s just that in the greater scheme of things, account takeover is much more dangerous, much easier to implement, verified to be ubiquitous on the web today, and yet is almost completely unreported. We should address this and the Facebook problem but if we can do only one it should be this one. This post explains why, and how I’ve tried to address it over time.



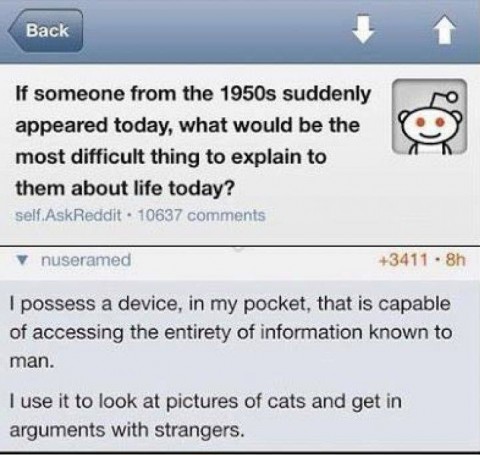 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my