 What would you do if you suddenly realized that your business model was indistinguishable from organized crime? Or, worse, what if you realized that your business directly harmed people economically and physically? Web Marketing has evolved to become the R&D lab for organized cybercrime and is currently in that unfortunate position. Here is the life cycle we are stuck in at present:
What would you do if you suddenly realized that your business model was indistinguishable from organized crime? Or, worse, what if you realized that your business directly harmed people economically and physically? Web Marketing has evolved to become the R&D lab for organized cybercrime and is currently in that unfortunate position. Here is the life cycle we are stuck in at present:
- Users find new ways to block ads and preserve (or at least fortify) their privacy.
- Marketing devises new adtech to circumvent user controls.
- Cybercriminals exploit adtech to deliver malicious payloads.
- Lather, Rinse, Repeat.
News reports of people whose bank accounts are emptied or their identities stolen by cybercriminals are all too familiar. Mostly forgotten however is that when some high-level SSL certificates were compromised a few years back, forged certificates were found proxying the communications of dissidents from inside of repressive countries to Twitter, Google, Facebook and so on. What people thought was completely secure communication was in fact transparent to the authorities. It is a certainty that people came to physical harm after the Certificate Authority was breached, and that breach was a result of malvertising.
How did we get here?
The problem is that Marketing believes that it is in the business of creating content and cannot get past that worldview. The reality is that in the age of popular press, then broadcast radio and television, Marketing was reinvented as the world’s first micropayment system. Diverting a timeslice of the attention that a massive audience paid to the program content, and substituting commercial content, created a revenue stream out of thin air. With a large enough audience the aggregate value of attentional time slices could be monetized predictably and in sufficient quantity to fund both the content and the overhead of the micropayment system that generates the revenue.
What Marketing has lost sight of (or perhaps never realized) is that their primary business is distilling and aggregating micropayments to fund content, not in creation of content itself. Yes, it’s called “marketing” and that implies signal from advertisers to consumers. But marketing delivered in the context of program content is invisible if nobody likes the program content. No matter what you spend on a Superbowl ad, people who don’t like football won’t watch the game to see the ad. Funding content is primary. Making content is a means to that end but need not be in the age of the Internet.
How can it be fixed?
In the world of bulk print media, and of broadcast radio and TV, signal goes only one way and advertising content was required to close the signaling loop. It created an information stream from consumers in the form of increased sales and revenue. In the world of atoms, it was actually necessary to prevent the possibility of consumers responding en masse and overwhelming the seller.
But we do not need that anymore. The Internet closes the signaling loop much more effectively. Consumers can send signal upstream without overwhelming the recipient in the process. We are finally in a position to skip the commercial content and just pay directly for program content. But people don’t want to manage a million subscriptions and vendors don’t necessarily want to do that either. This is especially true when the lowest practical direct payment is significantly greater than the value of the content provided. So we still need to aggregate micro-revenue streams and distribute funds back to content creators. The difference is that we no longer need that to be driven by marketing content.
In a world where it is possible to track every second of content performance, directly funding content through subscription aggregation should be easy to do transparently, accountably, and without the invasive malicious technology. Marketing owns this space but that’s due only to historical legacy. Unless they remove the blinders with “content creator” printed on the inside they’ll soon cede it to someone else. Content creators just need funding and if they can get it without annoying the crap out of their patrons, and especially without delivering malvertising along with their content, they would be happy to do so. Content creators do not need to sell Bud Light. They just need funds.
Will Marketing step up?
When it comes to building a subscription aggregation ecosystem, Marketing currently holds a marginal advantage in its existing relationships with content creators and distribution outlets. This would help in the construction of a subscription bundling ecosystem if only Marketing realized they need to build it. But that advantage is eroding quickly as the Internet commoditizes those advantages so time is of the essence. Direct funding of program content is coming whether Marketing builds it or not. If they wait too long, they lose their main delivery channel as content goes ad-free.
Isn’t Marketing also content?
Creation of content, that thing Marketing seems to believe is their primary business model, is still required but as a subordinate function. It has been pointed out many times that sellers have a need to get information about their products out to the buying public and Marketing fills that need. Fair enough. But if you are in the market for a widget then marketing information about widgets is the program content and it will be sought out on that basis.
Anyone surfing the web ad-free who is in the market for widgets will – surprise! – want to compare widget features, read reviews on widgets, check widget prices, look for things that might fit their needs better than widgets, etc. The role of Marketers for these people will be to make sure that the information exists and is easy to find. Their role will not be to invade the privacy of potential consumers, attempting to claim every possible attentional timeslice by bombarding the consumer from all sides every waking second with brand messages. In an ad-free environment consumers will self-select to receive Marketing content at the point in time that it is relevant to them.
When advertising is voluntary and opt-in, *all* advertising is precisely targeted and extremely valuable.
Let me repeat that for Marketers whose attention timeslice I didn’t get the first time:
When advertising is voluntary and opt-in, *all* advertising is precisely targeted and extremely valuable. No Big Data crunching required. No invasive ad-tech required. No need to cover every visual or auditory blank space with branding. Furthermore, assuming the system monetizes sales rather than clicks or impressions, Every. Single. View. Or. Click. Is. Legitimate. Full stop.
Our current opt-out approach and consequent oversupply of marketing messages drives the incremental value of individual ads ever lower. But it is a mistake to believe that the value of an ad can never be less than zero. An oversupply of ads can in fact create negative value, especially when delivered coercively as is explained in the next section.
An autistic point of view
There is a relatively new model of autism called the Intense World Theory. Past theories of autism have assumed it arises from functional deficits in the human brain. But Intense World Theory posits that much of typical autistic behavior results from over-stimulation. This model explains so much better things such as texture sensitivity, physical agitation such as hand flapping or head banging in response to strong stimuli, and situational escalation leading to autistic meltdowns.
Marketing when and where a consumer requests it is an essential service. Marketing as it is practiced today on the web is more like a zombie apocalypse. Nobody actually wants to be attacked from all sides, relentlessly, by mindless things that just want a piece your brain, but Marketing refuses to believe that and plows ahead undeterred. When we put up defenses, Marketing invents new tech to circumvent them and tells us it has an absolute right to do so. This is an “essential truth” as one marketer recently put it. When we get infected and come to harm through malvertising, Marketing disclaims any responsibility.
Ask anyone familiar with autism and Intense World Theory what they would predict consumer response to be to Marketing’s current approach of carpet-bombing the consumer’s attentional landscape. Marketers tell us that the web depends on this model, that everyone involved is better off for it, and that they have a right to get their branding messages into our field of attention. But Intense World Theory tells us that beyond a certain point, people begin to feel violated, overwhelmed and out of control. They withdraw from the stimulation or find ways to defeat it, even to the point of self-destructive behavior if the stimulus is intense enough.
Head banging, hand flapping and body tics are how an autistic increases signal in order to drown out noise. Ad-Block+, Ghostery and other consumer-side controls perform the same function with respect to Marketing. Escalation of confrontation leads to a meltdown in the case of an autistic person, or to Congressional hearings in the case of invasive adtech. The parallels are obvious and the outcomes predictable.
You don’t need to be autistic to respond this way. Dial up the unwanted stimulus enough and everyone eventually gets to this point. Don’t believe me? Watch the reactions to the sound of fingernails on a blackboard. This is the first time in history that it has been possible to so thoroughly invade an individual’s cognitive space so we have not previously driven neurotypical people to autistic defensive behavior. Now that we are beginning to do so, we should recognize the response as predictable given the level of stimulus and move to change the approach. At the very least Marketing needs to dial down the stimulus. Better yet, Marketing should relate to people as respected peers rather than as subjects. Our attention is a privilege, not a right.
Suggestions
Marketing needs to reinvent itself as a funding aggregator for content first, and as the delivery of brand messages second.
- Create content subscription bundles so a single subscription reduces or eliminates ads across most or all web properties. Cybercrime cannot ride in on your rails once you rip up the track.
- Remunerate providers proportionally.
- Make sure independent content providers can get paid on par with large providers. Some might even say indie content is more valuable.
- Stop with the invasive adtech already. We hate it and we hate you for it.
- Make it easy for prospective consumers to find your brand messages when they are actually in the market for something.
- Turn your commercial content into program content. Remember the people who aren’t football fans who don’t watch the game to see the ads? They do go watch them on YouTube and vote on them in contests. We don’t mind brand messages if the content is compelling. (Clue!)
- Finally, and this applies to pretty much any business, if your business model is indistinguishable from and directly enables organized crime, don’t spend a minute rationalizing the harm caused. CHANGE THE MODEL.
Marketers, the countdown clock is ticking. Will you continue on the current path, eventually driving the public to a meltdown?
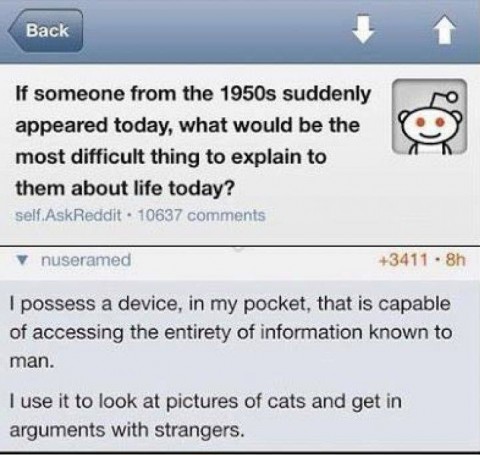 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my 


