
Would you give your account ID, password, account numbers, email address, home address, and all your other sensitive personal information to random strangers? No? Are you sure? Scripts embedded in a web page or app allow the script provider to record every keystroke and every mouse movement you make on the page.
So why are so many of the scripts on account management pages hosted by 3rd parties?


 Many news reports of late have described malware being delivered through advertising networks. But that leaves the impression that the AdTech itself is benign and being hijacked for nefarious purposes. While it may have started out that way, that is definitely not the case today. Kaspersky Labs mention several times in
Many news reports of late have described malware being delivered through advertising networks. But that leaves the impression that the AdTech itself is benign and being hijacked for nefarious purposes. While it may have started out that way, that is definitely not the case today. Kaspersky Labs mention several times in  What would you do if you suddenly realized that your business model was indistinguishable from organized crime? Or, worse, what if you realized that your business directly harmed people economically and physically? Web Marketing has evolved to become the R&D lab for organized cybercrime and is currently in that unfortunate position. Here is the life cycle we are stuck in at present:
What would you do if you suddenly realized that your business model was indistinguishable from organized crime? Or, worse, what if you realized that your business directly harmed people economically and physically? Web Marketing has evolved to become the R&D lab for organized cybercrime and is currently in that unfortunate position. Here is the life cycle we are stuck in at present: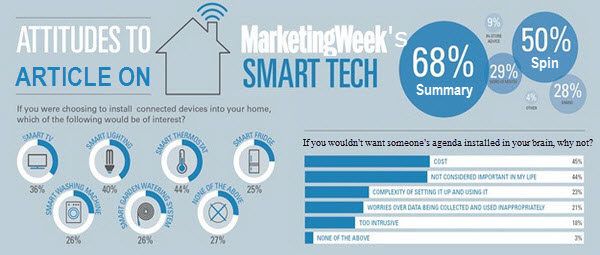 A few hours ago, Marketing Week published an article in their Trends section titled
A few hours ago, Marketing Week published an article in their Trends section titled 
 The one area in which the authors found some nuance was privacy concerns. It is unfortunate that the result of granularity in this category is to drastically understate the relevance of privacy in consumer minds as compared to the other categories. The effect is apparent in the summary that Marketing Week uses when referring to the article from elsewhere on the site: Consumers cite cost and lack of usefulness as barriers to adoption. No, they didn’t. If you combine both of the Privacy categories, there is a total of only 6 percentage points separating Cost (45%), Relevance (44%), and Privacy (39%). Complexity (23%), which is the next closest category, comes in a distant 12 points below Privacy. The concerns expressed seem to cluster around Cost, Relevance and Privacy as the barriers to adoption. Odd that privacy would get dropped like that.
The one area in which the authors found some nuance was privacy concerns. It is unfortunate that the result of granularity in this category is to drastically understate the relevance of privacy in consumer minds as compared to the other categories. The effect is apparent in the summary that Marketing Week uses when referring to the article from elsewhere on the site: Consumers cite cost and lack of usefulness as barriers to adoption. No, they didn’t. If you combine both of the Privacy categories, there is a total of only 6 percentage points separating Cost (45%), Relevance (44%), and Privacy (39%). Complexity (23%), which is the next closest category, comes in a distant 12 points below Privacy. The concerns expressed seem to cluster around Cost, Relevance and Privacy as the barriers to adoption. Odd that privacy would get dropped like that.
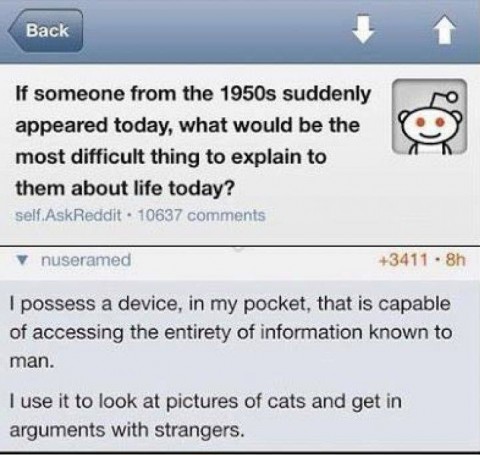 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my 
