My main issue with vendors turning us into instrumented data sources isn’t the data so much as the lack of consent. My Fitbit knows a lot about me but it’s an add-on that I self-selected and it provides value to me. The tracking in my browser is not something I can easily avoid since the browser is now an integral part of my life. Between those extremes there are lots of IoT devices that you can currently choose a private version but where that choice is rapidly disappearing. You can still buy a dumb light switch but not a dumb car, for example. Your shiny new GT phones home.
Among the vendors who seem to feel an entitlement to our data is Microsoft, whose Windows 10 is basically a box of spyware disguised as a user-productivity-gaming-and-cat-video-watching platform. I’ve already written about the issues there, how to mitigate them, and the disheartening number of those “features” that can’t be disabled. Yet as bad as all that is, this latest revelation still managed to surprise me across several metrics: the lack of consent, the extent of the invasion, the degree of exposure, the fact that it’s already been exploited to infect user devices, the fact that the entity who exploited it is a “legitimate” vendor, and the fact that said “legitimate” vendor egregiously exposed the exploit to the Internet. [Read more…]


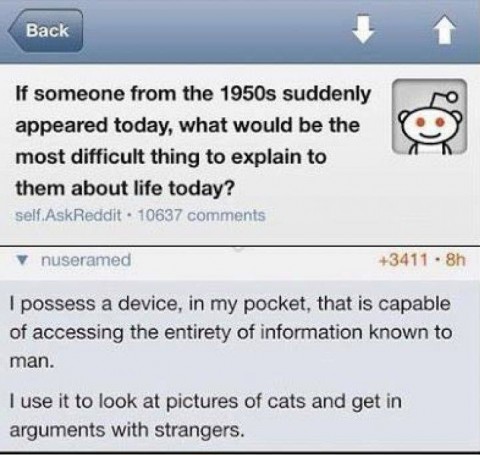 One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my
One of the currently popular Internet memes poses the question of what would be most difficult about today’s society to explain to a time traveler from the 1950’s. The reply calls us all out on our frivolous use of the massive amount of computing power available to all of us. The sentiment mirrors my 